Collections through webpages
The webpages data source feature allows you to efficiently gather and store content from various webpages. This collected information can then be leveraged to answer your customers' questions effectively. This document serves as a comprehensive guide on using the Website Ingestion feature, focusing on how to configure it and providing illustrative examples for clarity.
Configuration
Below are the parameters you can use to configure the ingestion process:
Full website
This collection starts with a seed URL. Seed URLs are the starting points for your crawl. They act as the base addresses from which the crawler begins exploring links. The crawler visits only those URLs that match the seed URLs or belong to their subdirectories.
For example, if the seed URL is https://example.com/, the crawler explores that page and all its linked subpages such as https://example.com/blog/, https://example.com/about-us/, etc.
Excluded URLs
Excluded URLs are those you want the crawler to ignore. You can specify them using the same format as seed URLs. The crawler does not visit any URLs that match the excluded URLs or belong to their subdirectories.
For example, if you exclude https://example.com/blog/, neither that page nor any pages under the blog directory will be visited.
Single URLs
Single URLs are pages you want the crawler to visit without following any links from them.
Sitemap URLs
Sitemap URLs enable the crawler to fetch a list of pages to visit. For example, https://example.com/sitemap.xml can be used to locate multiple URLs for ingestion.
Excluded assets
The crawler ignores certain assets such as images, CSS, JavaScript files, and PDFs. Below is the complete list of ignored file types:
- PNG
- JPG
- JPEG
- GIF
- CSS
- JS
Moveo crawls webpages every 24 hours. So you might not see the changes you make immediately.
Add a webpage
- Navigate to Build → Collections in the top navigation bar.
- Select the collection you want to add a webpage to, or create a new collection as described in the Collections overview.
- Navigate to the Webpages tab.
- Click the Add button to toggle the Add Webpage sidebar.
- Select which method of ingestion you want to use.
- Type the full URL of the webpage you want to add.
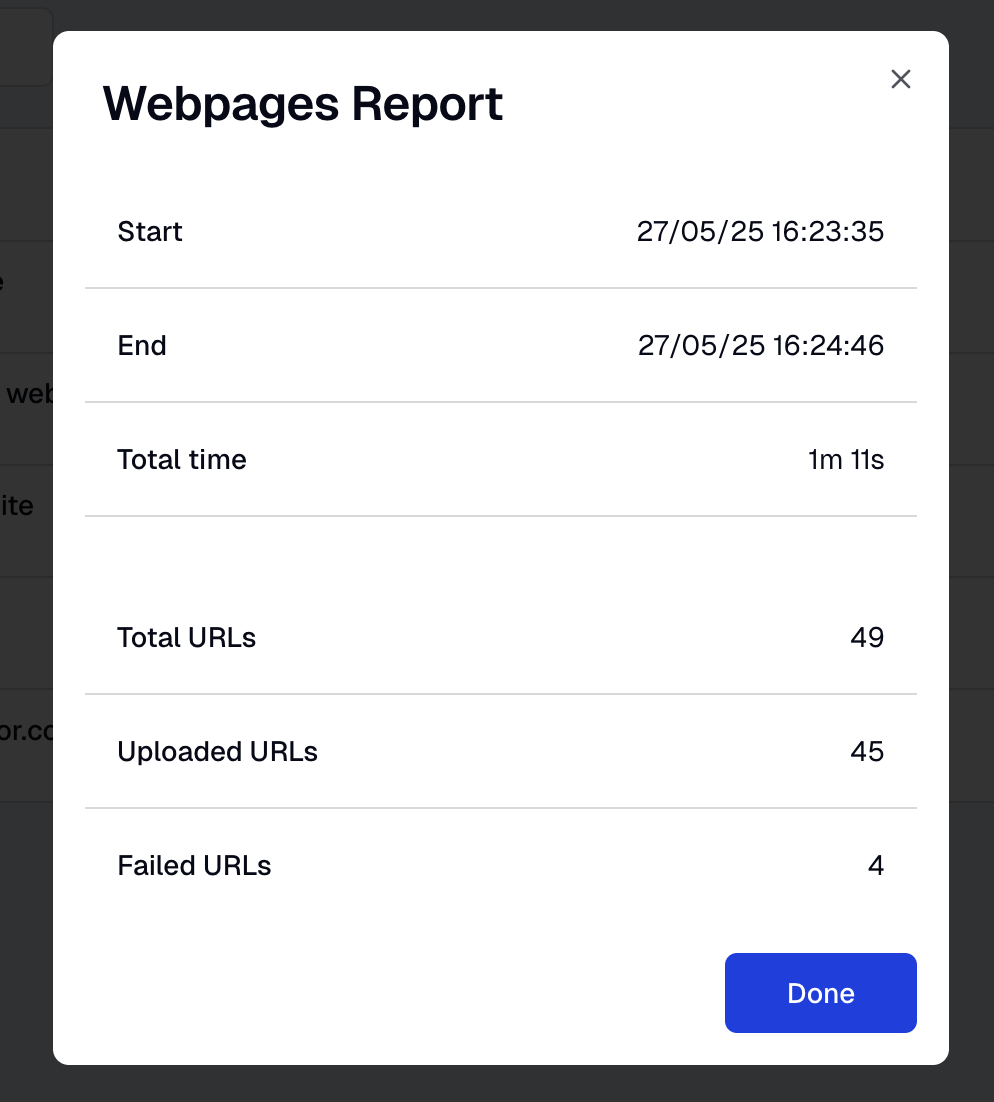
Ingestion report
The Ingestion Report provides details on the results of your webpage's data collection. By clicking on it, you can see how your site was ingested, the time it took, and any issues encountered (for example, problematic URL fields).
- Option
- Report
Troubleshooting
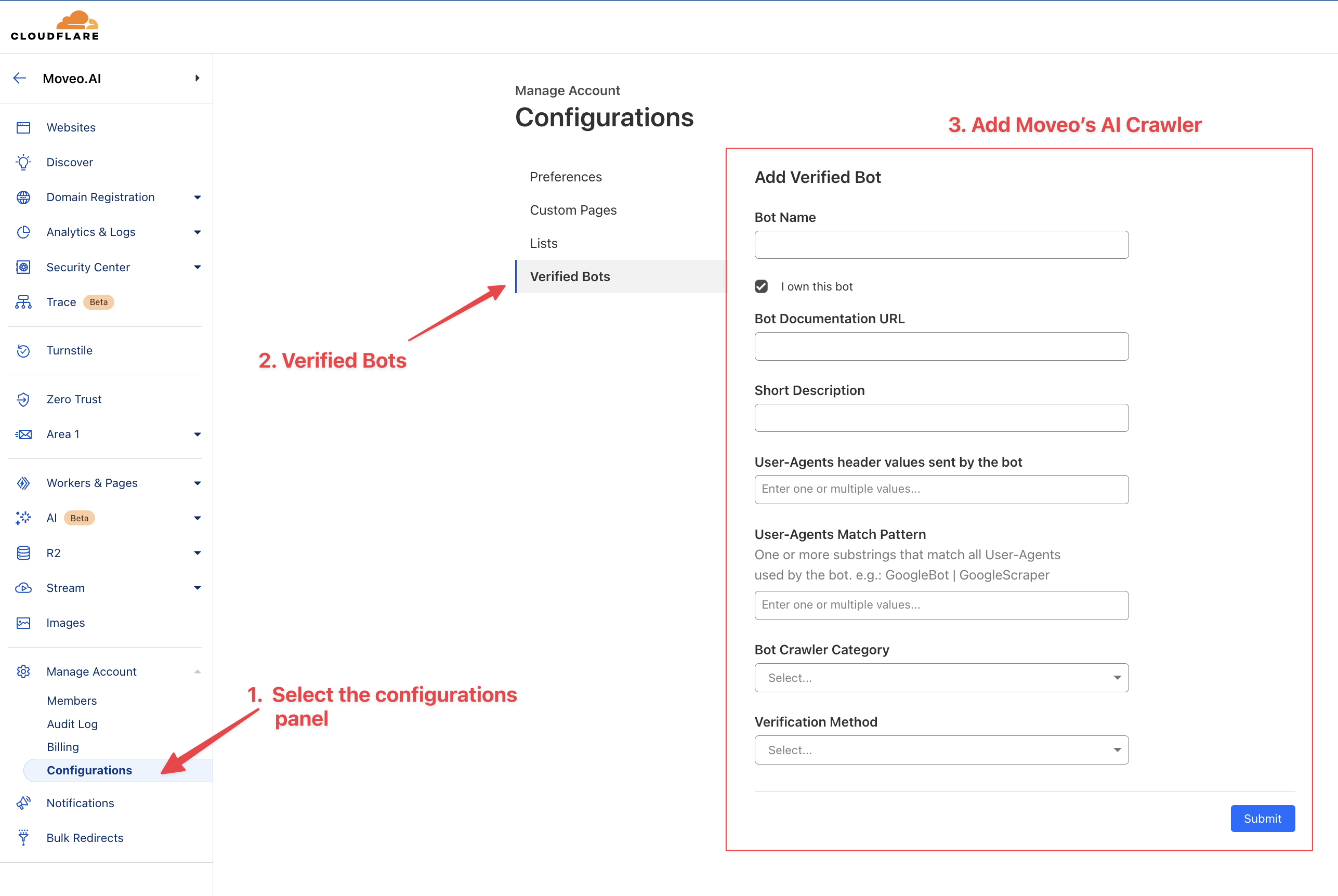
Sometimes, security services like Cloudflare might block the Moveo crawler from accessing a webpage. To prevent this, ensure that the Moveo crawler is included in your Verified bots list. In Cloudflare, navigate to Manage Account → Configurations → Verified Bots.
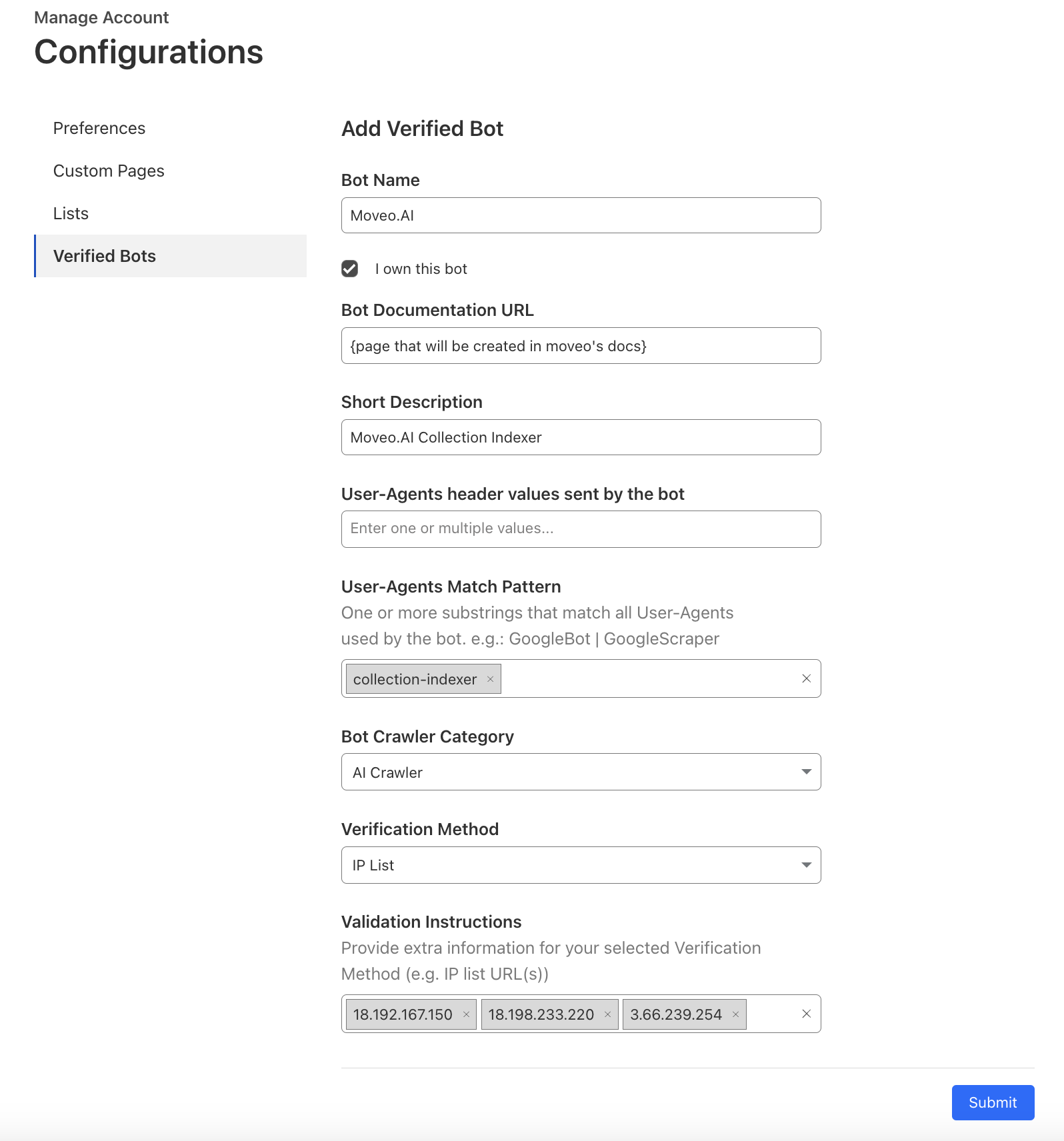
On that page, you should fill in the following details:
- Bot name: Moveo.AI
- User-Agents Match Pattern:
collection-indexer - Bot Crawler Category: AI Crawler
- Verification Method: IP List
- Validation Instructions:
18.192.167.150,18.198.233.220,3.66.239.254
- Cloudflare
- Add verified bot
Frequently asked questions
-
What file types are excluded during ingestion?
The crawler ignores files with extensions PNG, JPG, JPEG, GIF, PDF, CSS, and JS. -
Can I force the crawler to follow links from Single URLs?
No. Single URLs are crawled in isolation; the crawler does not follow any further links from them. -
Is there a way to view the status of my crawl?
Yes. Open the Ingestion Report, which outlines the process duration, URL issues, and any potential errors. -
How can I block the crawler from certain sections of my site?
You can list the paths or pages to be excluded under Excluded URLs. The crawler will ignore any URLs or subdirectories specified there. -
Can I use a sitemap for just one part of my webpage?
Absolutely. Point the crawler to any sitemap URL relevant to the sections you want to crawl. -
How do I resolve issues with Cloudflare blocking the crawler?
Add the Moveo crawler under Cloudflare's Verified Bots list with the specified IP addresses so it can access your webpage without hindrance. -
What happens if a URL is both in Seed URLs and Excluded URLs?
Excluded URLs take precedence. Any URL listed in Excluded URLs (or its subdirectories) will not be crawled. -
How can I integrate this with a site protected by login credentials?
At the moment, Moveo's crawler does not support authentication. You must provide publicly accessible URLs to be crawled. -
Does Moveo process JavaScript on my webpage?
Currently, the crawler focuses on static HTML content. If your webpage relies heavily on JavaScript for rendering, consider providing static versions of critical content for more complete indexing.